Overview
This project simulates a predator-prey pursuit in a 7×7 gridworld with obstacles. The planning for prey is modeled using a POMDP framework, while the predator uses the A* path planning algorithm. The goal is to observe how different strategies and environmental uncertainties affect pursuit outcomes.
Both agents operate on a grid with obstacles and simple movement rules. The prey actively plans by estimating the predator’s behavior, while the predator reacts based on known prey positions.

This image shows the simulated gridworld in the project. The red marker represents the predator, the blue marker represents the prey, and the green marker indicates the target. The black cells represent obstacles, while the white cells are free spaces
Prey Behavior
The planning for the prey is formulated using a Partially Observable Markov Decision Process (POMDP), consisting of the following components:
-
State space: The set of states consists of the predator and prey locations, represented by the 2D coordinates (x, y).
-
Action space:
– Movement actions in four cardinal directions (East, West, North, South).
– Look and Find actions allow the prey to observe the environment, gather new information, and update its beliefs when it reaches the target. -
Observation space:
– The predator’s position, target, and obstacles.
– If any of these are observed, their positions (or poses) are known; otherwise, they are not included in the set.
– The Bresenham line algorithm is used by the prey to determine whether the target or predator is within its line of sight, provided it is not blocked by an obstacle. -
Belief state:
A histogram-based estimate of the prey’s and target’s locations, updated based on observation history. -
Reward function:
– Small negative reward (−1) for movement, look, or find actions.
– Large negative reward (−1000) if caught by the predator or colliding with an obstacle.
– Large positive reward (+1000) for reaching the target. -
Transition model:
The prey’s action leads to a probabilistic transition between states. -
Discount factor:
Chosen as 0.95.
The POMDP is solved using PO-UCT (Partially Observable Upper Confidence Bounds for Trees), a Monte Carlo Tree Search algorithm, implemented with the pomdp_py library.
Predator Behavior
The predator always knows the prey’s location and plans its movement using the A* algorithm. It moves one step at a time toward the prey, aiming to minimize distance. The prey’s uncertain motion is modeled in a way similar to its “look” and “find” actions.
Simulation Setup
At each time step of the episode the following occurs:
-
The prey takes an action based on its policy. Two uncertainties may arise:
– The positions of the target or predator may be unknown.
– The predator’s motion may not be fully predictable. -
If the prey reaches the target or is caught by the predator, the episode ends.
-
If the episode continues, the prey receives a new observation and updates its belief state.
-
The prey performs forward simulations, constructing a planning tree by simulating a fixed number of states (10).
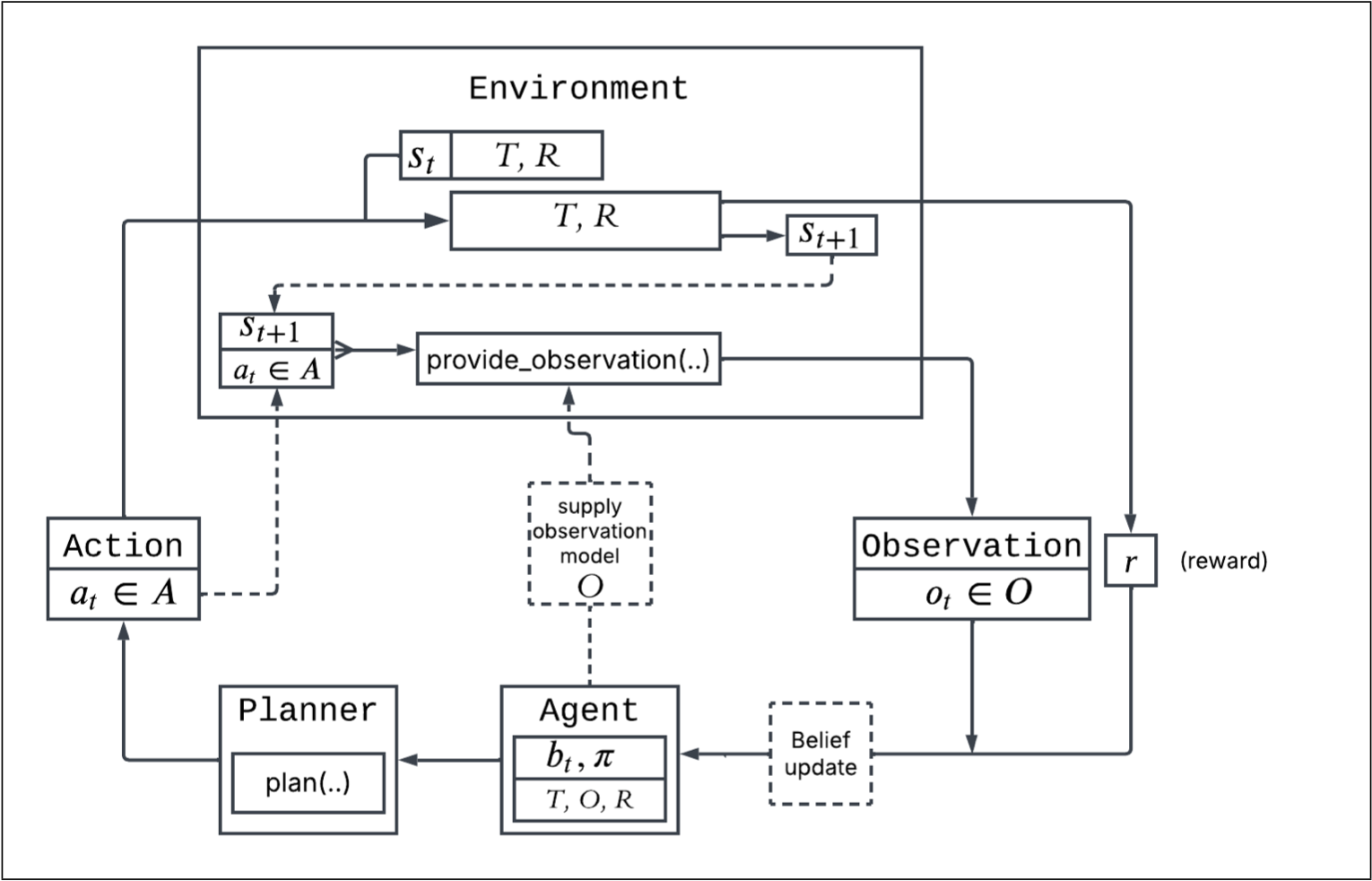
POMDP Control Flow
Results
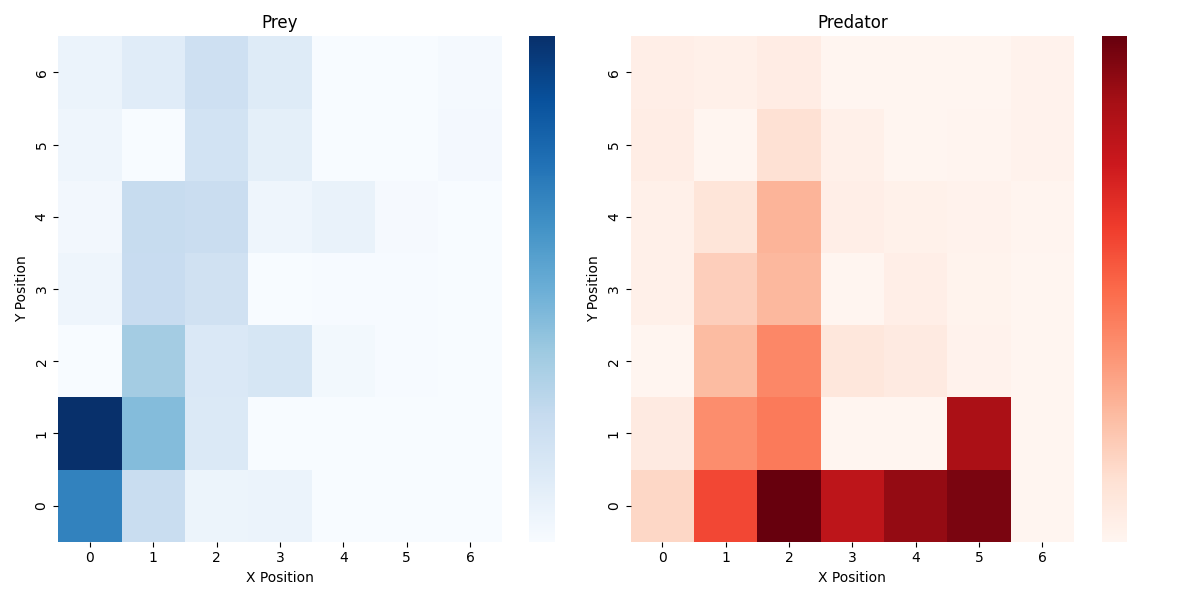
Heatmap of prey and predator over 100 simulations with color density proportional to the frequency of predator/prey over a cell
Code
All code and simulation outputs are available at https://github.com/phanikiran1169/decision_making_gridworld
References
-
Jack E. Bresenham. Algorithm for computer control of a digital plotter. IBM Systems Journal, 4(1):25–30, 1965.
-
Peter E. Hart, Nils J. Nilsson, and Bertram Raphael. A formal basis for the heuristic determination of minimum cost paths. IEEE Transactions on Systems Science and Cybernetics, 4(2):100–107, 1968.
-
Ugurcan Mugan and Malcolm A. MacIver. Spatial planning with long visual range benefits escape from visual predators in complex naturalistic environments. Nature Communications, 11(1):3057, 2020.
-
David Silver and Joel Veness. Monte-Carlo planning in large POMDPs. Advances in Neural Information Processing Systems, 23, 2010.
-
Kaiyu Zheng and Stefanie Tellex. pomdp.py: A framework to build and solve POMDP problems. arXiv preprint arXiv:2004.10099, 2020.